
Задача: разработать сервис для анализа товарного ассортимента розничного маркетплейса.
Была разработана система, которая парсит сайт-источник (маркетплейс) в реалтайм режиме, периодически отслеживая изменения в ценах на товары и услуги, а также изменения в предложениях относительно населенных пунктов и районов.
Массив спарсенных страниц, а также архив обработанных данных в динамике накапливается в базе данных для последующего анализа закономерностей в больших объемах данных.
Специально для возможности перепарсинга страниц в ретроспективе, для извлечения новых данных в архиве и исправления ошибок реализовано разделение процесса на извлечение содержимого и собственно парсинг страниц.
Извлечение данных подразумевает преодоление капчей (через antigate) и авторизацию под пользователями из автоматически созданного массива пользователей. Получение страниц осуществляется через массив анонимных прокси.
Автоматизация процесса парсинга подразумевает асинхронную постановку задач воркерам, распределенным в кластере серверов (через rabbitMQ и celery). Автоматическая оценка очереди асинхроннных воркеров позволяет гибко настраивать периодичность парсинга, для исключения избыточного накопления очереди из-за проблем в сети или перебоях в работе сайта-источника.
Система старается экономить ресурсы. При получении содержимого страницы, необходимого для парсинга разных типов объектов, запускается процесс парсинга одной и той же страницы, без повторного получения содержимого. HTTP-сессия, открытая для получения данных, по завершению выполнения задачи закрывается и упаковывается для следующей задачи. Это позволяет экономить на разгадке капчей.
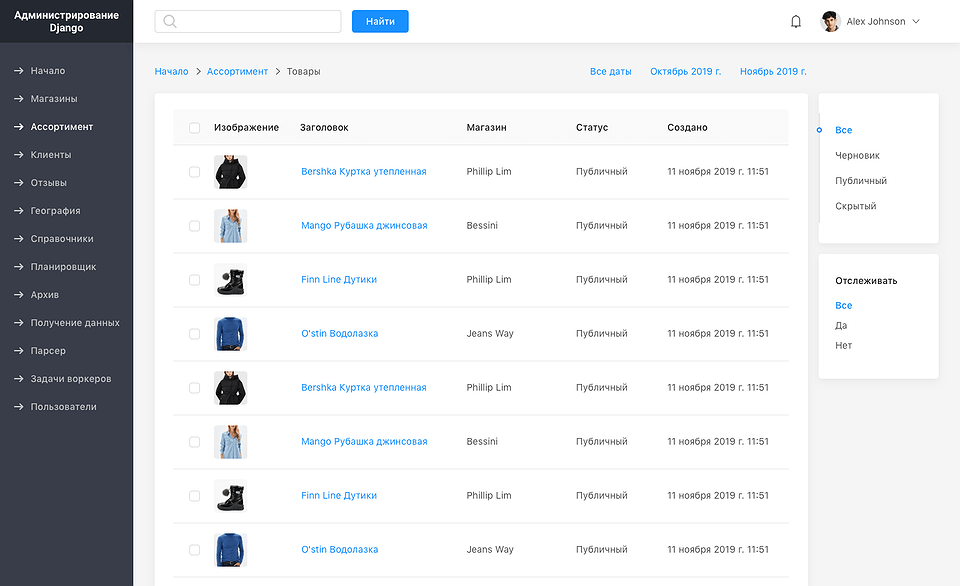
Для конечных пользователей системы создан фронтенд на Quasar Framework, где данные по товарам отражаются в таблицах с возможностью выгрузки в Excel и PDF. Географические данные отображаются на карте OSM посредством библиотеки leaflet. Данные генерализованы в зависимости от масштаба карты, что позволяет анализировать их на необходимом уровне детализации. Динамика цен и объема предложений выводится на графиках и диаграммах посредством ChartJS.
В результате мы получили готовую систему для парсинга большого массива данных с сайта-источника. Время разработки составило 250 часов. Создание аналога системы в будущем для другого источника с учетом переиспользования созданной кодовой базы потребует около 80 часов.
Если Вам необходимо разработать сложный парсер — пишите нам на order@idpowers.com.


